Summary
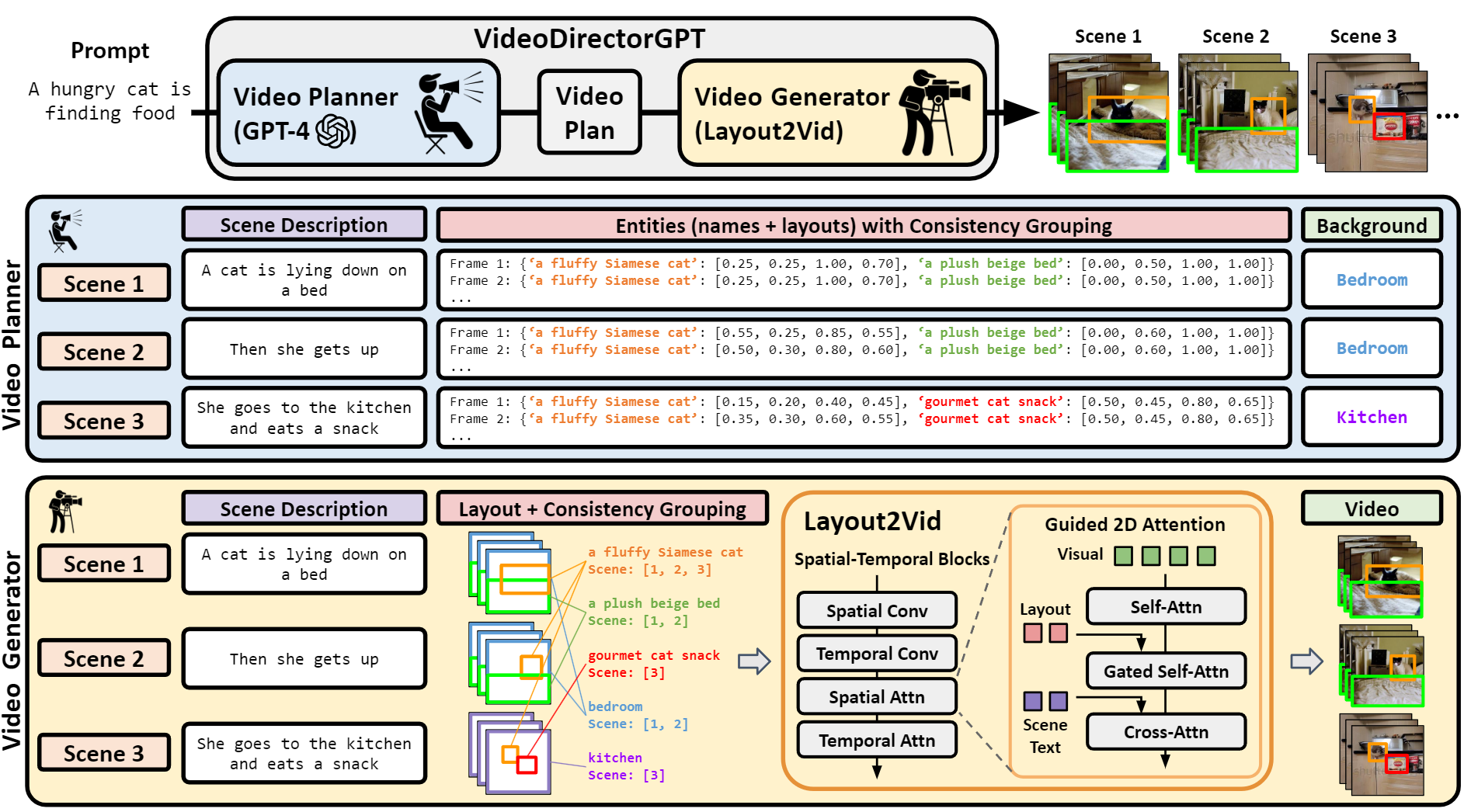
Video Planning: Generating Video Plans with LLMs
As illustrated in the blue part of Figure 1, GPT-4 (OpenAI, 2023) acts as a planner and provides a detailed video plan from a single text prompt to guide the downstream video generation. Our video plan consists of four components: (1) multi-scene descriptions: a sentence describing each scene, (2) entities: names along with their 2D bounding boxes, (3) background: text description of the location of each scene, and (4) consistency groupings: scene indices for each entity/background indicating where they should remain visually consistent.
In the first step, we use GPT-4 to expand a single text prompt into a multi-scene video plan. Each scene comes with a text description, a list of entities (names and their 2D bounding boxes), and a background. For this step, we construct the input prompt using the task instruction, one in-context example, and the input text from which we aim to generate a video plan. Subsequently, we group entities and backgrounds that appear across different scenes using an exact match. For instance, if the 'chef' appears in scenes 1-4 and 'oven' only appears in scene 1, we form the entity consistency groupings as {chef:[1,2,3,4], oven:[1]}. In the subsequent video generation stage, we use the shared representations for the same entity/background consistency groups to ensure they maintain temporally consistent appearances.
In the second step, we expand the detailed layouts for each scene using GPT-4. We generate a list of bounding boxes for the entities in each frame based on the list of entities and the scene description. For each scene, we produce layouts for 8 frames, then linearly interpolate the bounding boxes to gather bounding box information for denser frames (e.g., 16 frames). We utilize the [x0 , y0 , x1 , y1 ] format for bounding boxes, where each coordinate is normalized to fall within the range [0,1]. For in-context examples, we present 0.05 as the minimum unit for the bounding box, equivalent to a 20-bin quantization over the [0,1] range.
Video Generation: Generating Videos from Video Plans with Layout2Vid
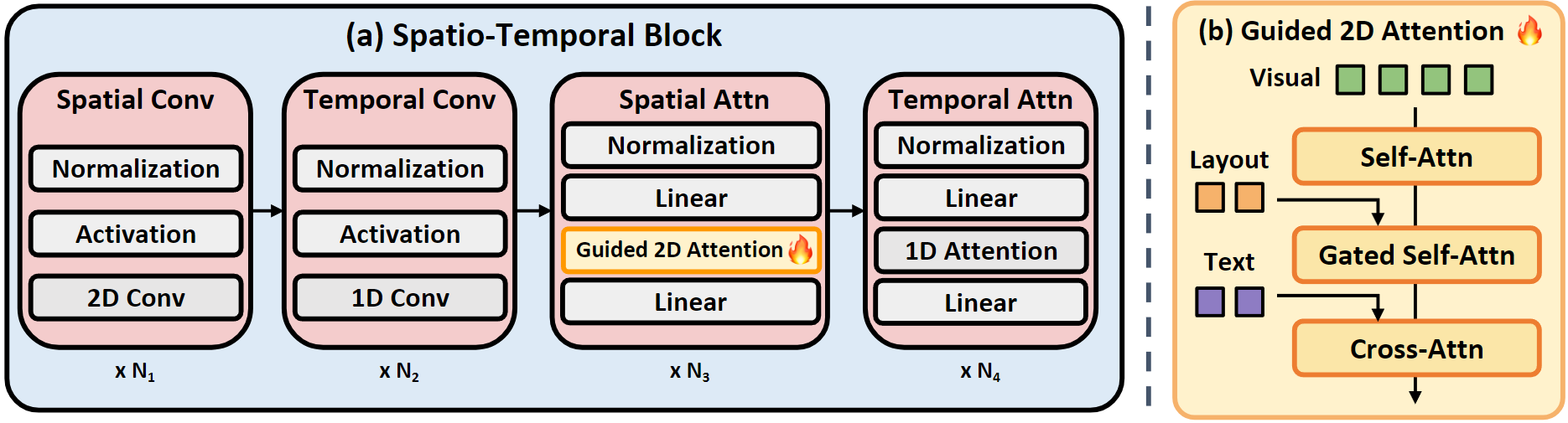
Our Layout2Vid module enables layout-guided video generation with explicit spatial control over a list of entities. These entities are represented by their bounding boxes, as well as visual and text content. As depicted in Fig. 2, we build upon the 2D attention mechanism within the spatial attention module of the spatio-temporal blocks in the Diffusion UNet to create the Guided 2D Attention. The Guided 2D Attention takes two conditional inputs to modulate the visual latent representation: (a) layout tokens, conditioned with gated self-attention, and (b) text tokens that describe the current scene, conditioned with cross-attention. Note that we train the Layout2Vid module in a parameter and data-efficient manner by only updating the Guided 2D Attention parameters (while other parameters remain frozen) with image-level annotations (no video-level annotations).
To preserve the identity of entities appearing across different frames and scenes, we use shared representations for the entities within the same consistency group. While previous layout-guided text-to-image generation models commonly only used the CLIP text embedding for layout control, we use the CLIP image embedding in addition to the CLIP text embedding for entity grounding.



































